

https://blog.ritsec.club/posts/afl-under-hood/
AFL++의 동작 과정을 자세히 분석한 위 글을 DeepL을 이용해 번역한 내용입니다.
일부 source, '여기'에 해당하는 링크는 누락되었을 수 있습니다.
AFL++와 Coverage-Based Fuzzing은 무엇입니까?
AFL은 무작위 입력 퍼저가 아닙니다. AFL은 커버리지 기반 퍼징이라는 것을 수행합니다. 커버리지 기반 퍼징의 기본 개념은 바이너리에서 어떤 영역이 실행되고 있는지 또는 커버리지가 있는지 추적하는 것입니다. 이 정보를 추적함으로써 어떤 입력이 코드의 어떤 부분을 실행하는지 파악할 수 있습니다. 이를 통해 코드베이스의 작은 하위 집합뿐만 아니라 전체 코드베이스를 포괄하는 입력 데이터베이스를 개발할 수 있습니다. 이렇게 하면 가장 일반적으로 사용되는 코드 경로뿐만 아니라 코드의 모든 곳에서 오류를 찾을 수 있습니다.
그렇다면 입력 데이터베이스, 즉 코퍼스를 어떻게 구축할 수 있을까요? 답은 반복입니다. 일반적으로 수동으로 생성된 몇 가지 시드 입력으로 시작합니다. 그런 다음 이러한 시드 입력을 무작위로 변경하여 커버리지에 변화를 일으키는지 확인합니다. 다른 잠재적 요인 중에서 커버리지에 변화를 일으키는 경우, 흥미로운 것으로 간주하여 추가 돌연변이를 위해 corpus에 저장합니다. 결국, 커져가는 corpus에서 반복적으로 돌연변이를 일으키고 나면 전체 코드베이스를 커버하는 corpus를 갖게 될 것입니다.
바라건대, 우리는 해당 입력이 목표로 하는 코드 경로에서 오류를 생성하는 방식으로 입력을 돌연변이할 수 있을 것입니다.
몇 가지 예제 코드를 통해 커버리지의 예를 살펴보겠습니다:
int main(){
input = get_input(); //stub that represents getting the input. Could be via a file, via stdin, or some other means.
if(condition A){
...code A...
}else if(condition B){
...code B ..
}else{
...code C...
}
return 0;
}프로그램에 시드 입력을 입력한다고 가정해 보겠습니다. 이 입력(시드)은 코드 C가 실행되도록 유도합니다.
그런 다음 씨앗을 어떤 식으로든 변이시켜 seed_A를 생성한다고 가정해 봅시다. 이 seed_A가 입력되면 코드 A가 실행됩니다. 이것은 새로운 것입니다. seed_A가 코드 A가 실행된다는 것을 알고 있으므로, 우리는 corpus에 seed_A를 저장하고 이를 더 변형하여 새롭고 다른 코드가 실행되도록 할 수 있습니다.
이처럼 새롭고 '흥미로운' 입력을 찾고 이를 기반으로 구축하는 반복적인 프로세스가 커버리지 기반 퍼징을 매우 강력하게 만드는 원동력입니다.
AFL++ 아키텍처
AFL++는 afl-fuzz 바이너리가 실행되면 시작됩니다. 명령은 일반적으로 다음과 같이 표시됩니다:
afl-fuzz -i [입력] -o [출력] -- /path/to/fuzzed/binary [@@]
일반적으로 @@은 프로세스가 읽는 입력 파일로 대체됩니다. 입력 파일이 제공되지 않으면 AFL은 프로세스가 stdin(또는 shmem)을 사용하여 입력을 받는다고 가정합니다.
-i는 시드 입력이 포함된 디렉터리입니다.-o는 출력이 배치될 디렉터리입니다.
afl-fuzz가 실행되면 일련의 초기화 함수가 실행됩니다. 그 후, afl-fuzz는 포크된 다음 대상 바이너리로 실행됩니다. 그러나 퍼징 자체는 afl-fuzz의 자식 프로세스에서 발생하지 않습니다. 대신, 자식 프로세스는 메인 프로세스 바로 전에 중지되어 "포크 서버" 역할을 합니다. 그런 다음 이 포크 서버가 다시 포크되고 손자 프로세스에서 퍼징이 발생합니다. 그 이유는 포크가 실행보다 훨씬 빠르기 때문입니다. 따라서 자식보다 손자손녀에서 퍼징을 수행하는 것이 훨씬 빠릅니다. 이 프로세스에 대해서는 더 자세히 설명하겠습니다.
afl-fuzz가 대상 바이너리와 통신하기 위해 제어 파이프와 상태 파이프(소스)라는 두 개의 파이프가 생성됩니다. 제어 파이프는 FORKSRV_FD(보통 198)에 위치하며, 대상 바이너리에 대해 읽기 전용이고 afl-fuzz에 대해 쓰기 전용입니다. 상태 파이프는 FORKSRV_FD+1에 위치하며 대상 바이너리는 쓰기 전용이고 afl-fuzz는 읽기 전용입니다.
제어 파이프는 대상 바이너리에 제어 메시지를 보내는 데 사용됩니다. 상태 파이프는 afl-fuzz로 상태 메시지를 보내는 데 사용됩니다.
이제 afl-fuzz가 하는 일을 개략적으로 이해했으니 바이너리가 어떻게 생겼고 어떤 일을 하는지 자세히 살펴봅시다.
Coverage Instrumentation
AFL++가 제대로 작동하려면(적어도 정상 작동 모드에서는) 특수 AFL 컴파일러를 사용하여 바이너리를 컴파일해야 합니다. 이는 AFL이 커버리지를 추적하기 위해 특수 명령어를 삽입할 수 있도록 하기 위함입니다. 이러한 특수 명령어를 인스트럭션이라고 합니다. 일반적으로 계측 명령어는 커버리지 맵이라고 하는 것에 액세스합니다. 이 커버리지 맵은 코드의 어떤 부분에 액세스했는지 기록합니다.
AFL은 현재 다양한 형태의 커버리지를 지원하지만, 가장 일반적이고 잘 지원되는 두 가지 커버리지는 PCGUARD와 LTO입니다.
PCGUARD부터 시작하겠습니다. PCGUARD 계측을 사용하려면 afl-clang-fast를 사용해야 합니다. PCGUARD를 이해하기 위해 Ghidra/lldb에서 PCGUARD로 컴파일된 바이너리를 살펴봅시다:
디컴파일된 C:

어셈블리:
AFL에서 커버리지 맵은 __afl_area_ptr입니다. __afl_area_ptr은 새 영역에 도달할 때마다 액세스되는 배열입니다. 이는 디컴파일된 C에서 확인할 수 있습니다. 함수 상단, if 문 및 else 문에 __afl_area_ptr에 대한 액세스가 있는 것을 확인할 수 있습니다.
PCGUARD에서 액세스하는 __afl_area_ptr의 인덱스는 런타임에 결정됩니다. *특히 DAT** 변수의 값은 런타임에 채워집니다. 이는 인덱스가 rax에 로드되는 movxd가 있는 어셈블리에서 확인할 수 있습니다. 이 프로세스는 초기화에 대해 설명할 때 더 자세히 살펴보겠습니다.
여담이지만, 어셈블리에서 adc dl, 0을 주목하세요. 이는 add dl, 1이 감싸면 dl != 0이 되고, add dl, 1이 감싸면 CF=1이 되도록 하기 위함입니다. 따라서 adc dl, 0은 dl=1이 됩니다.
이제 LTO에 대해 알아보겠습니다. LTO 커버리지는 afl-clang-lto 컴파일러를 사용하여 달성할 수 있습니다. LTO 적용 범위는 런타임이 아닌 컴파일 타임에 __afl_area_ptr에 대한 인덱스가 채워진다는 점을 제외하면 PCGUARD와 매우 유사합니다.
이는 LTO 바이너리의 디컴파일된 C에서 확인할 수 있습니다:
__afl_area_ptr에 대한 인덱스가 변수가 아닌 immediate인 것을 주목하세요.
커버리지, 삽입 방법 및 일반적인 구현 세부 사항에 대한 자세한 내용은 심층 섹션을 확인하시기 바랍니다: AFL 컴파일러의 내부를 다루는 커버리지 계측 및 LLVM Hell 섹션을 참조하세요.
초기화와 포크서버
초기화 프로세스에 대해 설명하기 전에 초기화 배열이라고 하는 ELF의 기능에 대해 살펴볼 필요가 있습니다.
바이너리가 실행되면 메인이 실행되지 않습니다. 대신 항상 인터프리터(보통 ld.so)로 시작합니다. 인터프리터는 동적 연결과 같은 프로세스를 위한 많은 주요 구조를 설정합니다. 그러나 인터프리터의 잘 알려지지 않은 기능은 초기화 함수를 실행하는 기능입니다. 이러한 초기화 함수는 .init_array라는 섹션에 있습니다. 이 섹션에는 메인 바로 전에 순서대로 실행되는 함수 배열이 포함되어 있습니다.
.init_array의 함수는 바이너리가 PCGUARD로 컴파일되었는지 LTO로 컴파일되었는지에 따라 달라집니다(하지만 대부분 동일합니다).
.init_array의 함수에 대해 설명하면서 많은 변수, 환경 변수, 매크로가 있을 것입니다. 사용하기 쉽도록 아래에 모든 변수의 정의를 정리해 두었습니다:
정규 변수:
__afl_area_ptr- 커버리지 맵 포인터입니다. 기본값은__afl_area_initial입니다.__afl_area_initial의 크기는MAP_INITIAL_SIZE입니다.__afl_final_loc- 계측이 액세스한__afl_area_ptr의 마지막 인덱스__afl_map_addr- 커버리지 맵이 mmap'd될 주소입니다. 제가 알기로는AFL_LLVM_MAP_ADDR이 LTO 모드로 설정된 경우에만 실제로 존재합니다. 그렇지 않으면 0입니다.__afl_map_size- 커버리지 맵의 크기__afl_area_initial- 공유 메모리가 매핑되기 전과 공유 메모리에 액세스할 수 없는 경우(즉, AFL에서 실행 중이 아닌 경우) 사용되는 커버리지 맵입니다. 이는 afl-compiler-rt.o.c에서 배열로 생성됩니다.
환경 변수:
__AFL_SHM_ID(SHM_ENV_VAR로 별칭) - 커버리지 맵의 공유 메모리 ID.__AFL_SHM_FUZZ_ID(별칭: SHM_FUZZ_ENV_VAR) - 공유 메모리 퍼징을 위한 공유 메모리 ID.AFL_MAP_SIZE- afl-fuzz에 할당된 공유 메모리 버퍼의 크기를 설정하는 데 사용됩니다.
매크로:
MAP_SIZE- 공유 메모리 맵의 크기를 강제로 지정하는 데 사용할 수 있는 사용자 지정 값입니다.MAP_INITIAL_SIZE-__afl_area_initial의 크기 PCGUARD부터 시작해 봅시다. init 함수는 다음과 같습니다:

각 함수를 살펴보겠습니다. 이 모든 함수(sancov.module_ctor_trace_pc_guard 제외)는 afl-compiler-rt.o.c에서 찾을 수 있습니다.
먼저 __afl_auto_first부터 시작하겠습니다. 이 함수는 아무것도 하지 않습니다. 이 함수가 하는 일은 __afl_already_initialized_first = 1을 설정하는 것뿐입니다.
다음 함수는 __afl_auto_second입니다. PCGUARD의 경우 이 함수는 아무 작업도 수행하지 않습니다. 이 시점에서 __afl_final_loc = 0이기 때문입니다. 이것이 실제로 다음 함수에서 초기화되는 것을 볼 수 있습니다.
다음 함수는 sancov.module_ctor_trace_pc_guard입니다. 이것은 실제로 아래에서 볼 수 있듯이 __sanitizer_cov_trace_pc_guard_init에 대한 호출일 뿐입니다. 이 호출이 어떻게 구성되는지에 대한 자세한 내용은 '심층 분석'을 확인하시기 바랍니다: 커버리지 인스트루먼트 및 LLVM Hell" 섹션을 참조하세요.
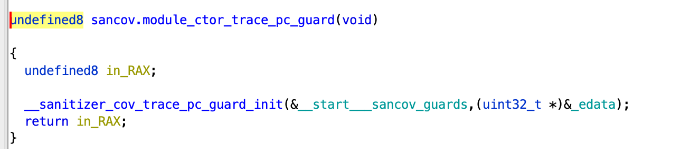
__sanitizer_cov_trace_pc_guard_init은 계측에서 본 _*afl_final_loc 및 DAT** 변수를 초기화하는 함수입니다. 이 함수를 좀 더 자세히 살펴보겠습니다:
void __sanitizer_cov_trace_pc_guard_init(uint32_t *start, uint32_t *stop) {
u32 inst_ratio = 100;
char *x;
_is_sancov = 1;
...
if (start == stop || *start) return;
...
if (__afl_final_loc < 3) __afl_final_loc = 3; // we skip the first 4 entries
*(start++) = ++__afl_final_loc; //start at 4
while (start < stop) {
if (likely(inst_ratio == 100) || R(100) < inst_ratio)
*start = ++__afl_final_loc;
else
*start = 0; // write to map[0]
start++;
}
...
}따라서 이 함수는 start과 stop이라는 두 개의 매개변수를 받습니다. 이것은 가드 섹션의 시작과 끝, 즉 모든 DAT\ 변수가 있는 섹션을 나타냅니다. 우리가 하는 일은 전체 가드 섹션을 살펴보고 모든 DAT\ 변수를 인덱스로 채우면서 afl_final_loc을 증분하는 것입니다. 그 결과 `afl_final_loc`은 커버리지가 액세스하는 최종 인덱스와 같게 됩니다.
이렇게 하면 모든 DAT_* 변수가 채워지고 계측이 준비됩니다.
다음 함수는 __afl_auto_early입니다. 이 함수는 실제로 afl-fuzz에서 커버리지에 액세스할 수 있게 해주는 함수입니다. __afl_auto_early를 이해하려면 먼저 공유 메모리에 대해 알아볼 필요가 있습니다. 공유 메모리는 여러 프로세스에서 액세스할 수 있는 메모리를 만드는 데 사용되는 Linux의 기능입니다. 각 공유 메모리 인스턴스에는 이를 고유하게 식별하는 고유 ID가 있습니다. 두 프로세스가 동일한 공유 메모리에 액세스하려면 둘 다 동일한 ID로 공유 메모리를 매핑하기만 하면 됩니다. 공유 메모리에 대한 자세한 내용은 매뉴얼 페이지를 참조하세요.
기본적으로 afl-fuzz는 공유 메모리 인스턴스를 생성하고 대상 프로세스는 해당 공유 메모리 설명자를 커버리지 맵으로 매핑합니다. 결과적으로 afl-fuzz는 하위 프로세스가 커버리지 맵에 변경하는 모든 변경 사항을 볼 수 있습니다.
따라서 __afl_auto_early는 실제로 모든 작업을 수행하는 __afl_map_shm을 호출합니다. 이 함수는 많은 엣지 케이스를 다루지만 여기서는 afl-fuzz에서 실행하는 경우에 대해서만 설명하겠습니다. __afl_map_shm의 길이 때문에 설명하는 대신 관련 코드에 주석을 달기로 했습니다.
static void __afl_map_shm(void) {
if (__afl_already_initialized_shm) return;
__afl_already_initialized_shm = 1;
// afl에서 실행하지 않는 경우 맵이 존재하는지 확인합니다.
if (!__afl_area_ptr) { __afl_area_ptr = __afl_area_ptr_dummy; }
char *id_str = getenv(SHM_ENV_VAR); //공유 메모리 ID를 가져옵니다.
if (__afl_final_loc) { //에지가 있는 경우 항상 참이어야 합니다.
__afl_map_size = ++__afl_final_loc; // 크기가 아니라 액세스한 최종 인덱스이므로 __afl_final_loc을 증가시킵니다.
...
if (__afl_final_loc > MAP_SIZE) { //공유 메모리 맵이 수용할 수 있는 것보다 많은 에지가 있으면 문제가 발생할 수 있습니다.
char *ptr;
u32 val = 0;
if ((ptr = getenv("AFL_MAP_SIZE")) != NULL) { val = atoi(ptr); }
if (val < __afl_final_loc) { //if AFL_MAP_SIZE < __afl_final_loc이면 맵이 충분히 크지 않을 수 있습니다.
if (__afl_final_loc > FS_OPT_MAX_MAPSIZE) { //필요한 지도 크기가 너무 큽니다. AFL에서 실행하는 경우 떠나야 합니다. AFL에서 실행하지 않는 경우 필요한 메모리를 간단히 할당하면 됩니다. 이에 대한 자세한 내용은 심층 분석: afl-fuzz 초기화를 참조하세요.
if (!getenv("AFL_QUIET"))
fprintf(stderr,
"Error: AFL++ tools *require* to set AFL_MAP_SIZE to %u "
"to be able to run this instrumented program!\n",
__afl_final_loc);
if (id_str) {
send_forkserver_error(FS_ERROR_MAP_SIZE);
exit(-1);
}
} else { //if AFL_MAP_SIZE > MAP_INITIAL_SIZE, 할당된 맵 크기가 *일부* 너무 작을 수 있습니다. 이에 대한 자세한 내용은 심층 도움말: afl-fuzz 초기화를 참조하세요.
if (__afl_final_loc > MAP_INITIAL_SIZE && !getenv("AFL_QUIET")) {
fprintf(stderr,
"Warning: AFL++ tools might need to set AFL_MAP_SIZE to %u "
"to be able to run this instrumented program if this "
"crashes!\n",
__afl_final_loc);
}
}
}
}
} else {
...
}
}
...
u32 shm_id = atoi(id_str); //shm_id를 가져옵니다. 이것은
if (__afl_map_size && __afl_map_size > MAP_SIZE) {
u8 *map_env = (u8 *)getenv("AFL_MAP_SIZE");
if (!map_env || atoi((char *)map_env) < MAP_SIZE) {
send_forkserver_error(FS_ERROR_MAP_SIZE);
_exit(1);
}
}
__afl_area_ptr = (u8 *)shmat(shm_id, (void *)__afl_map_addr, 0); //map을 공유 메모리에 저장하고 __afl_area_ptr과 동일하게 설정합니다. 여기서부터 계측기는 더미 메모리에 액세스하는 대신 공유 메모리에 액세스하게 되며, 따라서 변경 사항이 afl-fuzz에 표시됩니다.
/* Whooooops. */
if (!__afl_area_ptr || __afl_area_ptr == (void *)-1) {
if (__afl_map_addr)
send_forkserver_error(FS_ERROR_MAP_ADDR);
else
send_forkserver_error(FS_ERROR_SHMAT);
PERROR("SHMAT FOR MAP");
_exit(1);
}
/* AFL_INST_RATIO가 낮더라도 부모가 포기하지 않도록 비트맵에 뭔가를 씁니다,
부모가 우리를 포기하지 않도록 비트맵에 뭔가를 작성합니다. */
__afl_area_ptr[0] = 1;
}
...
}이렇게 하면 __afl_area_ptr이 설정되어 공유 메모리를 가리키게 됩니다.
이제 __early_forkserver로 이동합니다. 이 함수는 초기 포크 서버를 요청하지 않는 한 아무 일도 하지 않습니다.
마지막 함수는 __afl_auto_init입니다. 이 함수에서는 실제로 afl-fuzz와 통신하고 테스트 케이스를 실행하기 시작합니다. __afl_auto_init에서는 __afl_manual_init을 호출하고, 이 함수는 다시 __afl_start_forkserver를 호출합니다. 여기서 함수의 핵심이 발생합니다.
첫 번째 중요한 스니펫은 아래와 같습니다:
if (__afl_map_size <= FS_OPT_MAX_MAPSIZE) {
status_for_fsrv |= (FS_OPT_SET_MAPSIZE(__afl_map_size) | FS_OPT_MAPSIZE);
}
if (__afl_dictionary_len && __afl_dictionary) {
status_for_fsrv |= FS_OPT_AUTODICT;
}
if (__afl_sharedmem_fuzzing) { status_for_fsrv |= FS_OPT_SHDMEM_FUZZ; }
if (status_for_fsrv) {
status_for_fsrv |= (FS_OPT_ENABLED | FS_OPT_NEWCMPLOG);
}
memcpy(tmp, &status_for_fsrv, 4);
/* Phone home and tell the parent that we're OK. If parent isn't there,
assume we're not running in forkserver mode and just execute program. */
if (write(FORKSRV_FD + 1, tmp, 4) != 4) { return; }이 코드 조각의 기본 아이디어는 기본적으로 afl-fuzz에 대상 바이너리에 대해 알려주는 것입니다. 맵 크기, 사전이 있는지 여부, 공유 메모리 퍼징을 사용하는지 여부에 대해 알려줍니다. 그런 다음 그 결과를 앞서 설명한 대로 상태 파이프(afl-fuzz로 상태 메시지를 보내는 데 사용되는)인 FORKSRV_FD+1에 씁니다.
여기에서 실제 퍼징을 수행하는 동안 루프에 들어갑니다. 읽기 쉽도록 주석을 달았습니다:
while (1) {
int status;
/* 파이프에서 읽어서 부모를 기다립니다. 읽기에 실패하면 중단합니다. */
if (already_read_first) {
already_read_first = 0;
} else {
if (read(FORKSRV_FD, &was_killed, 4) != 4) {
_exit(1);
}
}
...
/* 영구 모드에서 자식을 멈췄지만, 경쟁
조건이 있고 afl-fuzz가 이미 sigkill을 발행했다면, 이전
프로세스를 삭제합니다. */
if (child_stopped && was_killed) {
child_stopped = 0;
if (waitpid(child_pid, &status, 0) < 0) {
write_error("child_stopped && was_killed");
_exit(1);
}
}
if (!child_stopped) {
/* 깨어나면 프로세스의 복제본을 생성합니다. */
child_pid = fork(); //프로세스를 포크합니다. 손자손녀를 실행합니다.
if (child_pid < 0) {
write_error("fork");
_exit(1);
}
/* 자식 프로세스에서: fds를 닫고 실행을 재개합니다. */
//유념: 포크는 자식에 대해 0을 반환하고 부모에 대해 자식 pid를 반환합니다.
if (!child_pid) {
//(void)nice(-20);
signal(SIGCHLD, old_sigchld_handler); //신호 핸들러를 리셋합니다.
signal(SIGTERM, old_sigterm_handler);
close(FORKSRV_FD); //파이프를 닫습니다.
close(FORKSRV_FD + 1);
return; //메인으로 복귀
}
} else {
/* 퍼시스턴트 모드에 대한 특별 처리: 자식이 살아있지만
현재 중지된 경우, SIGCONT로 다시 시작하면 됩니다. */
kill(child_pid, SIGCONT);
child_stopped = 0;
}
/* 부모 프로세스에서: PID를 파이프에 쓴 다음 자식을 기다립니다. */
if (write(FORKSRV_FD + 1, &child_pid, 4) != 4) { //부모에게 손자손녀의 PID를 알려줍니다.
WRITE_ERROR("WRITE TO AFL-FUZZ");
_exit(1);
}
if (waitpid(child_pid, &status, is_persistent ? WUNTRACED : 0) < 0) { //자녀가 완료될 때까지 기다립니다.
WRITE_ERROR("WAITPID");
_exit(1);
}
/* 퍼시스턴트 모드에서, 자식은 SIGSTOP으로 스스로를 중지하여
로 자식을 중지합니다. 이 경우 다시 포크하지 않고 깨우고 싶습니다.
를 다시 호출합니다. */
if (WIFSTOPPED(status)) child_stopped = 1;
/* 대기 상태를 파이프로 전달한 다음 다시 반복합니다. */
if (write(FORKSRV_FD + 1, &status, 4) != 4) { //부모에게 완료되었음을 알립니다. 이렇게 하면 부모에게 커버리지 맵을 확인하고 재설정하거나 변경할 수 있는 기회가 주어집니다.
WRITE_ERROR("WRITING TO AFL-FUZZ");
_exit(1);
}
}위의 코드는 본질적으로 포크 서버입니다. 기본적으로 퍼징을 수행하기 위해 자식을 계속 포크합니다.
이 모든 기능을 통해 퍼저가 설정되었고 성공적으로 퍼징을 수행하고 있습니다. 그러나 퍼징을 훨씬 더 빠르게 수행할 수 있는 방법이 있습니다.
Persistent Mode
Persistent 모드는 퍼징을 더 빠르게 수행할 수 있는 방법입니다. 일반적으로 퍼징을 할 때는 테스트 케이스를 실행할 때마다 프로그램을 다시 시작해야 합니다. 하지만 코드의 작은 하위 집합 하나를 테스트하고 싶다면 어떨까요? 이때는 Persistent모드가 유용합니다.
AFL++ 문서에 따르면, Persistent 모드에서는 "AFL++는 퍼즈를 실행할 때마다 새 프로세스를 포크하는 대신 하나의 포크된 프로세스에서 대상을 여러 번 퍼즈합니다."(출처). Persistent 모드를 설명하기 위해 예제를 살펴보는 것이 더 쉽습니다. 다음 코드 스니펫을 살펴보세요:
#include "what_you_need_for_your_target.h"
main() {
// anything else here, e.g. command line arguments, initialization, etc.
unsigned char buf[1024];
while (__AFL_LOOP(10000)) { //loop
int len = read(0,buf,1024);
if (len < 8) continue; // check for a required/useful minimum input
target_function(buf, len);
memset(buf, 0, 1024); //reset the state
/* Reset state. e.g. libtarget_free(tmp) */
}
return 0;
}Persistent 모드로 실행하면 포크 서버가 약간 변경됩니다. 구체적으로 waitpid 조건이 변경됩니다. 이는 아래 if 문에서 확인할 수 있습니다:
if (waitpid(child_pid, &status, is_persistent ? WUNTRACED : 0) < 0)바이너리가 Persistent이면 자식이 종료되는 대신 중지될 때까지 기다립니다(WUNTRACED). 그 이유는 __afl_persistent_loop로 확장되는 __AFL_LOOP 매크로에서 찾을 수 있습니다.
이 함수의 기본 개념은 남은 루프 수에 해당하는 정적 변수 cycle_cnt가 있다는 것입니다. 모든 루프가 끝날 때마다(cycle_cnt = 0이 되면 멈추는 시점 제외) SIGSTOP을 발생시킵니다. 이렇게 하면 위의 waitpid 조건이 트리거되어 afl-fuzz가 돌연변이를 수행하고 커버리지 맵을 재설정할 수 있습니다. 제어권이 포크 서버로 반환되면, 바이너리는 SIGCONT를 통해 재개됩니다.
이 루프 구조는 종종 매우 느릴 수 있는 바이너리를 다시 시작하지 않고도 루프 내의 코드 섹션을 여러 번 실행할 수 있게 해줍니다.
공유 메모리 퍼징
공유 메모리 퍼징은 퍼징 속도를 더욱 빠르게 만드는 방법입니다. 일반적으로 대상 바이너리는 stdin 또는 명령줄 인수로 전달된 파일에서 읽습니다. 하지만 이 방법은 읽기 시스템 호출이 필요하기 때문에 속도가 느릴 수 있습니다. 그렇다면 어떻게 하면 더 빠르게 만들 수 있을까요?
정답은 공유 메모리 퍼징입니다. 커버리지 맵이 공유 메모리인 것과 같은 방식으로 입력도 공유 메모리로 만듭니다. 이렇게 하면 afl-fuzz가 입력 테스트 케이스를 파일 대신 공유 메모리 버퍼에 쓸 수 있습니다.
공유 메모리 퍼징을 용이하게 하려면 소스 코드를 약간 수정해야 합니다. 아래 코드 스니펫을 살펴보세요:
#include "what_you_need_for_your_target.h"
__AFL_FUZZ_INIT();
main() {
// anything else here, e.g. command line arguments, initialization, etc.
unsigned char *buf = __AFL_FUZZ_TESTCASE_BUF; // must be after __AFL_INIT
// and before __AFL_LOOP!
while (__AFL_LOOP(10000)) {
int len = __AFL_FUZZ_TESTCASE_LEN; // don't use the macro directly in a
// call!
if (len < 8) continue; // check for a required/useful minimum input length
/* Setup function call, e.g. struct target *tmp = libtarget_init() */
/* Call function to be fuzzed, e.g.: */
target_function(buf, len);
/* Reset state. e.g. libtarget_free(tmp) */
}
return 0;
}위의 소스 코드에서는 공유 메모리 퍼징을 활성화했습니다. __AFL_FUZZ_TESTCASE_BUF는 실제 테스트케이스 버퍼입니다. 이 버퍼는 공유 메모리 영역을 가리킵니다. 이 메모리 영역은 루프 사이에 업데이트됩니다. __AFL_FUZZ_TESTCASE_LEN은 공유 메모리 영역 내 데이터의 실제 길이입니다. 공유 메모리 퍼징을 이해하려면 초기화 프로세스를 살펴보는 것도 도움이 됩니다.
공유 메모리 퍼징을 위한 초기화는 __afl_map_shm_fuzz라는 함수에서 시작됩니다. 이 함수는 공유 메모리 퍼징이 감지될 때마다 __afl_start_forkserver에서 호출됩니다. 공유 메모리 퍼징은 공유 메모리가 사용될 때마다 1로 설정되는 변수 __afl_sharedmem_fuzzing을 통해 감지됩니다. 이 변수는 매크로 __AFL_FUZZ_INIT()가 사용될 때 1로 설정됩니다.
__afl_map_shm_fuzz는 __afl_map_shm과 매우 유사한 방식으로 작동합니다. 이 함수는 환경 변수 __AFL_SHM_FUZZ_ID(종종 SHM_FUZZ_ENV_VAR로 별칭 지정됨)에서 shmem ID를 가져옵니다(출처). 그런 다음 shmat를 실행하여 공유 메모리 영역을 프로세스에 매핑합니다.
영역이 매핑된 후에는 __afl_fuzz_len 및 __afl_fuzz_ptr(각각 __AFL_FUZZ_TESTCASE_LEN 및 __AFL_FUZZ_TESTCASE_BUF로 앨리어싱)을 다음과 같이 설정합니다:
__afl_fuzz_len = (u32 *)map;
__afl_fuzz_ptr = map + sizeof(u32);맵의 처음 4바이트가 실제로는 쓰여진 데이터의 크기이므로 __afl_fuzz_len이 실제로는 u32*라는 점에 유의하세요.
공유 메모리 퍼징과 퍼시스턴트 모드 퍼징의 작동 방식에 대해 더 자세히 알고 싶다면 여기 있는 데모 코드를 디버거나 Ghidra 같은 디어셈블러로 컴파일하고 분석해 보시기 바랍니다.
Sanitizers
메모리 오류(예: 버퍼 오버플로, 힙 오버플로, 사용 후 해제 등)는 어떻게 하냐고 묻는 분들이 많으시죠? 커버리지 계측이 이러한 오류를 탐지하는 데 어떻게 도움이 될 수 있을까요? 안타깝게도 커버리지 기반 퍼징은 메모리 오류를 탐지할 수 없습니다. 대신 새니타이저라는 것을 사용해야 합니다.
잘못된 메모리 액세스(예: UAF), 초기화되지 않은 메모리 사용, 정의되지 않은 동작 등 다양한 종류의 오류를 탐지하는 데 특화된 많은 종류의 새니타이저가 있습니다.
이들 중 일부는 매우 복잡할 수 있으므로 여기서는 설명하지 않겠습니다. 자세한 내용은 Google에서 각 소독제와 그 구현을 설명하는 멋진 위키를 게시했습니다.
심층 탐구: afl-fuzz 초기화와 런타임 프로세스
afl-fuzz의 초기화
AFL++가 어떻게 퍼징하는지 이해하려면 afl_fuzz의 소스 코드를 살펴보는 것이 유용하며, 주요 함수는 여기에서 확인할 수 있습니다.
우리가 주목해야 할 두 가지 핵심 구조가 있습니다: afl_state_t와 afl_forkserver_t.
afl_state_t는 퍼저와 뮤테이터 파라미터, 옵저버, 피드백 등을 포함한 많은 파라미터를 관리하는 구조체입니다.
afl_forkserver_t는 포크 서버를 관리합니다. 포크서버는 나중에 자세히 설명하겠지만, 높은 수준에서 보면 퍼징할 바이너리를 실행하는 역할을 합니다. 이 구조에는 입력 파일과 포크 서버가 수행하는 작업에 대한 매개변수(Nyx? Qemu?) 등 기타 주요 정보가 포함되어 있습니다. afl_forkserver_t는 afl_state_t에 포함되어 있습니다.
afl-fuzz를 초기화하기 위해 afl-fuzz.c의 main에서 시작합니다. 여기에는 많은 내용이 있으며, 대부분은 QEMU 모드, Nyx 모드, Frida 모드 등과 같은 에지 케이스를 처리하기 위한 것입니다.
가장 먼저 중요한 것은 map_size를 가져오는 것입니다. 이것은 공유 메모리 커버리지 맵의 크기입니다. map_size를 가져오려면 get_map_size를 호출하여 다음을 수행합니다:
u32 get_map_size(void) {
uint32_t map_size = DEFAULT_SHMEM_SIZE;
char *ptr;
if ((ptr = getenv("AFL_MAP_SIZE")) || (ptr = getenv("AFL_MAPSIZE"))) {
map_size = atoi(ptr);
if (!map_size || map_size > (1 << 29)) {
FATAL("illegal AFL_MAP_SIZE %u, must be between %u and %u", map_size, 64U,
1U << 29);
}
if (map_size % 64) { map_size = (((map_size >> 6) + 1) << 6); }
} else if (getenv("AFL_SKIP_BIN_CHECK")) {
map_size = MAP_SIZE;
}
return map_size;
}기본적으로 크기가 8MB인 DEFAULT_SHMEM_SIZE를 사용합니다. 그렇지 않으면 AFL_MAP_SIZE 또는 AFL_MAPSIZE 환경 변수를 사용하여 맵 크기를 설정할 수 있습니다.
두 번째로 중요한 작업은 afl_state_t와 afl_forkserver_t를 초기화하는 것입니다:
afl_state_init(afl, map_size);
...
afl_fsrv_init(&afl->fsrv);이 두 함수는 몇 가지 중요한 변수를 설정합니다. afl_state_init은 아래와 같이 맵 크기를 map_size로 설정합니다:
afl->shm.map_size = map_size ? map_size : MAP_SIZE;afl_fsrv_init은 다음 변수를 설정합니다:
fsrv->out_fd = -1; //set out_fd to -1 by default
...
fsrv->use_stdin = true; //by default use stdin
...
fsrv->child_pid = -1; //set the child_pid to -1그런 다음 afl->shmem_testcase_mode = 1로 설정합니다. 이렇게 하면 가능하면 항상 공유 메모리 테스트 케이스를 사용하도록 합니다.
여기서부터 afl-fuzz는 명령줄 플래그를 실행하고 필요에 따라 저장합니다. 이러한 명령줄 인수의 대부분은 QEMU 또는 Frida와 같은 AFL의 다른 작동 모드를 처리하기 위한 것입니다. 하지만 우리가 신경 쓰는 명령줄 플래그가 하나 있습니다: 출력 디렉터리를 나타내는 -o입니다:
case 'o': /* output dir */
if (afl->out_dir) { FATAL("Multiple -o options not supported"); }
afl->out_dir = optarg;아래는 기본 파일 설정 코드입니다:
if ((afl->tmp_dir = afl->afl_env.afl_tmpdir) != NULL && !afl->in_place_resume)
...
} else {
afl->tmp_dir = afl->out_dir;
}
if (!afl->fsrv.out_file) {
u32 j = optind + 1;
while (argv[j]) {
u8 *aa_loc = strstr(argv[j], "@@");
if (aa_loc && !afl->fsrv.out_file) {
afl->fsrv.use_stdin = 0;
default_output = 0;
if (afl->file_extension) {
afl->fsrv.out_file = alloc_printf("%s/.cur_input.%s", afl->tmp_dir,
afl->file_extension);
} else {
afl->fsrv.out_file = alloc_printf("%s/.cur_input", afl->tmp_dir);
}
detect_file_args(argv + optind + 1, afl->fsrv.out_file,
&afl->fsrv.use_stdin);
break;
}
++j;
}
}
if (!afl->fsrv.out_file) { setup_stdio_file(afl); }여기서 afl->fsrv.out_file은 입력이 기록될 파일입니다.
위 코드에서는 몇 가지 작업을 수행합니다. 먼저 argv를 살펴보고 @@의 인스턴스를 찾으려고 합니다. 명령줄 인수로 입력을 전달할 경우 @@은 입력 파일로 대체된다는 점을 기억하세요. @@을 찾으면 기능적으로 sprintf에 해당하는 alloc_printf를 수행하여 테스트케이스가 쓰여질 경로를 구성합니다. 또한 명령줄 인수를 사용하고 있음을 나타내기 위해 afl->fsrv.use_stdin을 0으로 설정합니다.
사용되는 특정 경로는 [output dir]/.cur_input입니다. AFL_TMPDIR 환경 변수를 사용하여 출력 디렉터리가 아닌 다른 디렉터리를 사용하도록 강제할 수 있습니다. AFL++ 문서에 설명된 대로 이 방법은 성능을 향상시키는 램디스크 마운트 파일시스템을 가리킬 때 특히 유용합니다.
@@이 감지되지 않는 경우 setup_stdio_file을 실행합니다:
void setup_stdio_file(afl_state_t *afl) {
if (afl->file_extension) {
afl->fsrv.out_file =
alloc_printf("%s/.cur_input.%s", afl->tmp_dir, afl->file_extension);
} else {
afl->fsrv.out_file = alloc_printf("%s/.cur_input", afl->tmp_dir);
}
unlink(afl->fsrv.out_file); /* Ignore errors */
afl->fsrv.out_fd =
open(afl->fsrv.out_file, O_RDWR | O_CREAT | O_EXCL, DEFAULT_PERMISSION);
if (afl->fsrv.out_fd < 0) {
PFATAL("Unable to create '%s'", afl->fsrv.out_file);
}
}이것은 명령줄 인수의 코드와 놀랍도록 유사합니다. 하지만 @@ 대신 출력 파일을 연다는 점에 주목하세요. 그 이유는 나중에 살펴보겠습니다.
퍼저를 실행할 준비가 거의 다 되었습니다. 먼저 커버리지 맵과 공유 메모리 테스트 케이스 모두에 대한 공유 메모리 설명자를 설정해야 합니다.
공유 메모리 테스트 케이스 설정:
if (afl->shmem_testcase_mode) { setup_testcase_shmem(afl); }앞서 설명한 것처럼 afl->shmem_testcase_mode는 항상 1이므로 다음을 수행하는 setup_testcase_shmem을 실행합니다:
void setup_testcase_shmem(afl_state_t *afl) {
afl->shm_fuzz = ck_alloc(sizeof(sharedmem_t));
// we need to set the non-instrumented mode to not overwrite the SHM_ENV_VAR
u8 *map = afl_shm_init(afl->shm_fuzz, MAX_FILE + sizeof(u32), 1);
afl->shm_fuzz->shmemfuzz_mode = 1;
if (!map) { FATAL("BUG: Zero return from afl_shm_init."); }
#ifdef USEMMAP
setenv(SHM_FUZZ_ENV_VAR, afl->shm_fuzz->g_shm_file_path, 1);
#else
u8 *shm_str = alloc_printf("%d", afl->shm_fuzz->shm_id);
setenv(SHM_FUZZ_ENV_VAR, shm_str, 1);
ck_free(shm_str);
#endif
afl->fsrv.support_shmem_fuzz = 1;
afl->fsrv.shmem_fuzz_len = (u32 *)map;
afl->fsrv.shmem_fuzz = map + sizeof(u32);
}이 코드는 몇 가지 중요한 작업을 수행합니다. 먼저 afl_shm_init을 사용하여 실제 공유 메모리 영역을 생성합니다. 그런 다음 환경 변수 SHM_FUZZ_ENV_VAR을 설정합니다. 앞서 살펴본 바와 같이 이 환경 변수는 계측에서 공유 테스트케이스 메모리 영역을 설정하는 데 사용됩니다. 환경 변수를 설정하는 것 외에도 fsrv 변수도 설정합니다. afl->fsrv.shmem_fuzz_len = (u32 *)map; 을 주목하세요. 이는 앞서 계측 설정에서 __afl_fuzz_len = (u32*)map을 보았던 것과 일치합니다.
다음으로 공유 커버리지 맵을 설정합니다:
afl->fsrv.trace_bits =
afl_shm_init(&afl->shm, afl->fsrv.map_size, afl->non_instrumented_mode);
...
if (map_size <= DEFAULT_SHMEM_SIZE) {
afl->fsrv.map_size = DEFAULT_SHMEM_SIZE; // dummy temporary value
char vbuf[16];
snprintf(vbuf, sizeof(vbuf), "%u", DEFAULT_SHMEM_SIZE);
setenv("AFL_MAP_SIZE", vbuf, 1);
}이는 공유 테스트케이스 메모리가 설정되는 방식과 매우 유사하며, 다시 한 번 afl_shm_init을 사용하므로 크기가 afl->fsrv.map_size인 것을 알 수 있습니다. 또한 공유 메모리 크기를 어떻게 가져오는지 주목하세요.
이 모든 설정이 완료되면 마침내 포크 서버를 시작할 준비가 된 것입니다. 이 작업은 다음을 수행하는 afl_fsrv_get_mapsize를 통해 수행됩니다:
u32 afl_fsrv_get_mapsize(afl_forkserver_t *fsrv, char **argv,
volatile u8 *stop_soon_p, u8 debug_child_output) {
afl_fsrv_start(fsrv, argv, stop_soon_p, debug_child_output);
return fsrv->map_size;
}그런 다음 실제 작업을 수행하는 afl_fsrv_start를 호출합니다. 이 함수의 시작은 대부분 특정 옵션/작동 모드에 대한 매개변수를 설정하는 것입니다. 실제 작업은 파이프와 포크를 설정할 때 시작됩니다:
if (pipe(st_pipe) || pipe(ctl_pipe)) { PFATAL("pipe() failed"); }
...
fsrv->fsrv_pid = fork();여기에서 자녀와 부모에 개별적으로 집중할 수 있습니다. 자식에 대한 코드는 아래에서 볼 수 있습니다:
if (!fsrv->use_stdin) {
dup2(fsrv->dev_null_fd, 0);
} else {
dup2(fsrv->out_fd, 0);
close(fsrv->out_fd);
}
if (dup2(ctl_pipe[0], FORKSRV_FD) < 0) { PFATAL("dup2() failed"); }
if (dup2(st_pipe[1], FORKSRV_FD + 1) < 0) { PFATAL("dup2() failed"); }
close(ctl_pipe[0]);
close(ctl_pipe[1]);
close(st_pipe[0]);
close(st_pipe[1]);
...
/* This should improve performance a bit, since it stops the linker from
doing extra work post-fork(). */
if (!getenv("LD_BIND_LAZY")) { setenv("LD_BIND_NOW", "1", 1); }
/* Set sane defaults for sanitizers */
set_sanitizer_defaults();
fsrv->init_child_func(fsrv, argv);자식은 많은 일을 하지 않습니다. 먼저, 출력 입력에 stdin을 사용하는 경우, 앞서 설정한 out_fd를 가리키는 파일 설명자로 stdin을 대체합니다.
그런 다음, dup2를 사용하여 제어 파이프의 읽기 쪽을 FORKSRV_FD로, 상태 파이프의 쓰기 쪽을 FORKSRV_FD+1로 설정합니다. 이렇게 하면 자식이 올바른 파이프에 액세스할 수 있습니다. 그런 다음 모든 파이프를 닫아 불필요한 파일 디스크립터가 열려 있지 않도록 합니다.
그런 다음 fsrv->init_child_func(fsrv, argv)를 실행하여 실제로 자식 프로세스를 시작합니다.
부모로 이동해 봅시다. 부모는 훨씬 더 복잡합니다. 포크 직후의 코드부터 읽어보겠습니다:
close(ctl_pipe[0]);
close(st_pipe[1]);
fsrv->fsrv_ctl_fd = ctl_pipe[1];
fsrv->fsrv_st_fd = st_pipe[0];
/* Wait for the fork server to come up, but don't wait too long. */
rlen = 0;
if (fsrv->init_tmout) {
...
} else {
rlen = read(fsrv->fsrv_st_fd, &status, 4);
}먼저 제어 파이프의 읽기 끝과 상태 파이프의 쓰기 끝은 포크 서버에서 독점적으로 사용하므로 닫는 것으로 시작합니다.
그런 다음 제어 파이프의 쓰기 끝과 읽기 끝을 포크서버 로컬 변수로 설정하여 쉽게 액세스할 수 있도록 합니다.
그런 다음 여기에서 포크 서버가 보낸 상태 변수를 읽습니다. 이 상태 변수는 대상 바이너리에 대한 정보를 담고 있는 변수입니다. 기억하시겠지만, 이 변수는 포크 서버가 여기에서 보냈습니다.
이 상태 변수를 통해 포크서버는 필요한 옵션을 초기화하고 활성화합니다. 아래 두 개의 스니펫에서 이를 확인할 수 있습니다:
if ((status & FS_OPT_SHDMEM_FUZZ) == FS_OPT_SHDMEM_FUZZ) {
if (fsrv->support_shmem_fuzz) {
fsrv->use_shmem_fuzz = 1;
if (!be_quiet) { ACTF("Using SHARED MEMORY FUZZING feature."); }
if ((status & FS_OPT_AUTODICT) == 0 || ignore_autodict) {
u32 send_status = (FS_OPT_ENABLED | FS_OPT_SHDMEM_FUZZ);
if (write(fsrv->fsrv_ctl_fd, &send_status, 4) != 4) {
FATAL("Writing to forkserver failed.");
}
}
} else {
FATAL(
"Target requested sharedmem fuzzing, but we failed to enable "
"it.");
}
}위의 코드 조각에서는 공유 메모리 퍼징을 활성화하는 방법을 다룹니다. fsrv->support_shmem_fuzz != 1이면 공유 메모리 퍼징을 지원할 수 없습니다. 따라서 프로세스를 출력하고 종료합니다. 그렇지 않으면 fsrv->use_shmem_fuzz = 1로 설정하고 자식에게 공유 메모리 퍼징을 사용할 준비가 되었음을 알립니다.
if ((status & FS_OPT_MAPSIZE) == FS_OPT_MAPSIZE) {
u32 tmp_map_size = FS_OPT_GET_MAPSIZE(status);
if (!fsrv->map_size) { fsrv->map_size = MAP_SIZE; }
fsrv->real_map_size = tmp_map_size;
if (tmp_map_size % 64) {
tmp_map_size = (((tmp_map_size + 63) >> 6) << 6);
}
if (!be_quiet) { ACTF("Target map size: %u", fsrv->real_map_size); }
if (tmp_map_size > fsrv->map_size) {
FATAL(
"Target's coverage map size of %u is larger than the one this "
"afl++ is set with (%u). Either set AFL_MAP_SIZE=%u and restart"
" afl-fuzz, or change MAP_SIZE_POW2 in config.h and recompile "
"afl-fuzz",
tmp_map_size, fsrv->map_size, tmp_map_size);
}
fsrv->map_size = tmp_map_size;
}
위의 코드 조각에서는 지도 크기를 다루고 있습니다. 먼저 상태로부터 수신된 지도 크기를 가져와서 이를 tmp_map_size로 설정합니다. 그런 다음 해당 지도 크기를 할당된 지도 크기(fsrv->map_size)와 비교합니다. 수신된 지도 크기가 할당된 지도 크기보다 크면 큰 지도 크기를 수용할 수 없으므로 중단합니다.
이 시점에서 포크 서버가 완전히 설정되었으며, afl-fuzz의 런타임 프로세스를 조사할 준비가 되었습니다.
afl-fuzz의 런타임
AFL의 런타임 프로세스는 단일 do-while 루프에 있습니다:
do {
if (likely(!afl->old_seed_selection)) {
if (unlikely(prev_queued_items < afl->queued_items ||
afl->reinit_table)) {
// we have new queue entries since the last run, recreate alias table
prev_queued_items = afl->queued_items;
create_alias_table(afl);
}
do {
afl->current_entry = select_next_queue_entry(afl);
} while (unlikely(afl->current_entry >= afl->queued_items));
afl->queue_cur = afl->queue_buf[afl->current_entry];
}
skipped_fuzz = fuzz_one(afl);
...
if (unlikely(!afl->stop_soon && exit_1)) { afl->stop_soon = 2; }
if (unlikely(afl->old_seed_selection)) {
while (++afl->current_entry < afl->queued_items &&
afl->queue_buf[afl->current_entry]->disabled) {};
if (unlikely(afl->current_entry >= afl->queued_items ||
afl->queue_buf[afl->current_entry] == NULL ||
afl->queue_buf[afl->current_entry]->disabled)) {
afl->queue_cur = NULL;
} else {
afl->queue_cur = afl->queue_buf[afl->current_entry];
}
}
} while (skipped_fuzz && afl->queue_cur && !afl->stop_soon);위의 스니펫에서는 기본적으로 퍼징 대기열을 설정했습니다. 이 대기열은 퍼징의 다음 항목을 나타내지만, 솔직히 저는 AFL의 실제 변이 내부에 대한 전문가는 아닙니다.
하지만 퍼징의 핵심은 fuzz_one에서 이루어집니다. fuzz_one은 많은 변이 기능을 수행하는 방대한 함수이며 자체 기사로 다룰 만한 가치가 있습니다. 이 글에서는 포크 서버에 입력이 기록되는 부분과 포크 서버가 실행되는 부분으로 건너뛰겠습니다.
입력은 적절한 이름의 함수 common_fuzz_stuff에 기록됩니다. 아래는 관련 스니펫입니다:
u8 __attribute__((hot))
common_fuzz_stuff(afl_state_t *afl, u8 *out_buf, u32 len) {
u8 fault;
if (unlikely(len = write_to_testcase(afl, (void **)&out_buf, len, 0)) == 0) {
return 0;
}
fault = fuzz_run_target(afl, &afl->fsrv, afl->fsrv.exec_tmout);
...
}먼저 이름에서 알 수 있듯이 테스트 케이스를 입력 파일에 쓰는 write_to_testcase를 실행합니다. write_to_testcase는 많은 에지 케이스를 처리합니다. 그러나 주요 작업은 실제로 afl_fsrv_write_to_testcase에서 수행됩니다. 소스는 아래에서 확인할 수 있습니다:
if (likely(fsrv->use_shmem_fuzz)) {
if (unlikely(len > MAX_FILE)) len = MAX_FILE;
*fsrv->shmem_fuzz_len = len;
memcpy(fsrv->shmem_fuzz, buf, len);
...
} else {
s32 fd = fsrv->out_fd;
if (!fsrv->use_stdin && fsrv->out_file) {
if (unlikely(fsrv->no_unlink)) {
...
} else {
unlink(fsrv->out_file); /* Ignore errors. */
fd = open(fsrv->out_file, O_WRONLY | O_CREAT | O_EXCL,
DEFAULT_PERMISSION);
}
if (fd < 0) { PFATAL("Unable to create '%s'", fsrv->out_file); }
} else if (unlikely(fd <= 0)) {
// We should have a (non-stdin) fd at this point, else we got a problem.
FATAL(
"Nowhere to write output to (neither out_fd nor out_file set (fd is "
"%d))",
fd);
} else {
lseek(fd, 0, SEEK_SET);
}
// fprintf(stderr, "WRITE %d %u\n", fd, len);
ck_write(fd, buf, len, fsrv->out_file);
if (fsrv->use_stdin) {
if (ftruncate(fd, len)) { PFATAL("ftruncate() failed"); }
lseek(fd, 0, SEEK_SET);
} else {
close(fd);
}첫 번째 if 문은 공유 메모리 퍼징을 사용하는지 여부에 관한 것입니다. (fsrv->use_shmem_fuzz != 0)이면 입력을 공유 메모리 버퍼에 memcpy하고 그 길이를 기록하기만 하면 됩니다.
어떤 형태의 파일 입력을 사용하는 경우, 대신 else 문을 사용합니다.
먼저 fd를 가져오는 것으로 시작합니다. stdin을 사용하지 않는다면 if 문을 입력합니다. 이 if 문은 기존 fsrv->out_file의 링크를 해제(삭제)하고 새 파일을 만듭니다. stdin을 사용하는 경우에는 단순히 처음부터 다시 찾으면 됩니다.
이렇게 하면 ck_write를 통해 파일에 데이터를 씁니다. 이 작업이 완료되면 사실상 모든 작업이 완료된 것입니다. stdin을 사용하는 경우, 파일을 len 길이로 잘라내기도 합니다. 이렇게 하면 마지막 반복의 데이터가 남지 않습니다. 그런 다음 자식이 처음부터 읽을 수 있도록 마지막 한 번의 lseek을 수행합니다.
이 시점에서 변경된 입력이 기록됩니다. 이제 포크 서버를 다시 시작하기만 하면 됩니다. 이 작업은 fuzz_run_target에서 수행됩니다. 이 함수는 실제로는 단순히 타이머를 시작하고 afl_fsrv_run_target을 호출합니다. 이 함수의 대부분은 AFL의 대체 작동 모드를 다루기 때문에 관련 코드를 아래에 배치했습니다:
fsrv_run_result_t __attribute__((hot))
afl_fsrv_run_target(afl_forkserver_t *fsrv, u32 timeout,
volatile u8 *stop_soon_p) {
s32 res;
u32 exec_ms;
u32 write_value = fsrv->last_run_timed_out;
...
/* After this memset, fsrv->trace_bits[] are effectively volatile, so we
must prevent any earlier operations from venturing into that
territory. */
...
memset(fsrv->trace_bits, 0, fsrv->map_size);
MEM_BARRIER(); //commit all writes
/* we have the fork server (or faux server) up and running
First, tell it if the previous run timed out. */
if ((res = write(fsrv->fsrv_ctl_fd, &write_value, 4)) != 4) {
if (*stop_soon_p) { return 0; }
RPFATAL(res, "Unable to request new process from fork server (OOM?)");
}
fsrv->last_run_timed_out = 0;
if ((res = read(fsrv->fsrv_st_fd, &fsrv->child_pid, 4)) != 4) {
if (*stop_soon_p) { return 0; }
RPFATAL(res, "Unable to request new process from fork server (OOM?)");
}
...
exec_ms = read_s32_timed(fsrv->fsrv_st_fd, &fsrv->child_status, timeout,
stop_soon_p);
if (exec_ms > timeout) {
/* If there was no response from forkserver after timeout seconds,
we kill the child. The forkserver should inform us afterwards */
s32 tmp_pid = fsrv->child_pid;
if (tmp_pid > 0) {
kill(tmp_pid, fsrv->child_kill_signal);
fsrv->child_pid = -1;
}
fsrv->last_run_timed_out = 1;
if (read(fsrv->fsrv_st_fd, &fsrv->child_status, 4) < 4) { exec_ms = 0; }
}
if (!exec_ms) {
if (*stop_soon_p) { return 0; }
SAYF("\n" cLRD "[-] " cRST
"Unable to communicate with fork server. Some possible reasons:\n\n"
" - You've run out of memory. Use -m to increase the the memory "
"limit\n"
" to something higher than %llu.\n"
" - The binary or one of the libraries it uses manages to "
"create\n"
" threads before the forkserver initializes.\n"
" - The binary, at least in some circumstances, exits in a way "
"that\n"
" also kills the parent process - raise() could be the "
"culprit.\n"
" - If using persistent mode with QEMU, "
"AFL_QEMU_PERSISTENT_ADDR "
"is\n"
" probably not valid (hint: add the base address in case of "
"PIE)"
"\n\n"
"If all else fails you can disable the fork server via "
"AFL_NO_FORKSRV=1.\n",
fsrv->mem_limit);
RPFATAL(res, "Unable to communicate with fork server");
}
if (!WIFSTOPPED(fsrv->child_status)) { fsrv->child_pid = -1; }
fsrv->total_execs++;
/* Any subsequent operations on fsrv->trace_bits must not be moved by the
compiler below this point. Past this location, fsrv->trace_bits[]
behave very normally and do not have to be treated as volatile. */
MEM_BARRIER();
/* Report outcome to caller. */
/* Was the run unsuccessful? */
if (unlikely(*(u32 *)fsrv->trace_bits == EXEC_FAIL_SIG)) {
return FSRV_RUN_ERROR;
}
...
/* success :) */
return FSRV_RUN_OK;
}이 함수를 한 줄씩 살펴보겠습니다.
먼저 fsrv->trace_bits 또는 커버리지 맵에서 0으로 memset을 수행합니다. 이렇게 하면 커버리지 맵이 0이 되고 다음 실행을 위해 재설정됩니다.
이 작업이 완료되면 ctl_pipe를 통해 자식에게 씁니다. 이렇게 하면 다음 실행을 위해 자식이 깨어납니다.
그런 다음 상태 파이프에서 자식 PID를 읽습니다. 포크 서버는 포크 후 자식 PID를 상태 파이프에 기록한다는 것을 기억하세요.
이 작업이 성공했다고 가정하면, 자식 상태의 read_s32_timed를 수행합니다. read_s32_timed는 시간 제한이 있는 읽기입니다. 따라서 지정된 시간 초과 값이 만료되면 실제로 읽은 내용이 있는지 여부에 관계없이 읽기가 반환됩니다. 이렇게 하면 afl-fuzz가 매달린 자식이 될 수 있는 항목을 영원히 기다리지 않도록 할 수 있습니다. read_s32_timed에서 읽은 값은 여기서 __afl_start_forkserver에서 전달된 값과 동일합니다.
이 값이 반환되면 시간 초과가 만료되었는지 확인합니다. 시간 제한이 만료된 경우 오류 코드가 실행됩니다. 그런 다음 다음 코드를 실행합니다:
if (!WIFSTOPPED(fsrv->child_status)) { fsrv->child_pid = -1; }이 코드는 자식이 중지되었는지 확인합니다. 자식이 중지되지 않은 경우(즉, 종료된 경우) fsrv->child_pid = -1을 설정하여 다음 실행을 위해 PID를 지웁니다. Persistent 모드가 사용 중인 경우에만 자식을 중지할 수 있으며, Persistent 모드가 사용 중인 경우 자식이 다시 시작된다는 점을 기억하세요. 따라서 Persistent 모드가 사용 중인 경우 child_pid가 재사용되므로 fsrv->child_pid = -1을 설정하는 것은 유용하지 않습니다.
이 변경-쓰기-실행 루프는 치명적인 문제가 발생하거나 퍼저에 멈추라고 지시할 때까지 끝없이 실행됩니다.
심층 탐구: 커버리지 Instrumentation 과 LLVM Hell
afl-cc
그렇다면 커버리지 계측기는 실제로 어떻게 작동할까요?
계측이 실제로 어떻게 작동하는지 이해하려면 컴파일러 래퍼 afl-cc를 이해하는 것이 중요합니다. afl-cc는 실제 컴파일러(clang 또는 gcc)를 위한 C 래퍼로, 계측을 수행하는 데 필요한 모든 인수를 설정합니다. afl-cc의 소스는 여기에서 찾을 수 있습니다.
AFL 컴파일러를 사용하는 경우 afl-cc가 아니라 afl-clang-fast, afl-clang-lto, afl-gcc-fast 등을 사용할 가능성이 높다는 점에 유의하세요. 이들은 실제로 모두 afl-cc에 대한 심볼릭 링크입니다. afl-cc는 모든 주요 처리를 수행하고 컴파일러를 구분합니다.
어쨌든 AFL을 위해 컴파일할 때 다양한 형태의 도구를 사용할 수 있으며, 여기에 모두 잘 설명되어 있습니다. 이 글에서는 두 가지 종류의 계측에 초점을 맞추겠습니다: PCGUARD 계측과 LTO 계측입니다. PCGUARD 계측은 afl-clang-fast 컴파일러를 통해 액세스할 수 있으며, LTO 계측은 afl-clang-lto 컴파일러를 통해 액세스할 수 있습니다.
afl-cc의 소스 코드를 살펴보겠습니다.
afl-cc에서 우리가 실제로 신경 쓰는 변수는 세 가지입니다:
- compiler_mode: LLVM의 gcc를 사용하고 있나요? 어떤 종류의 LLVM을 사용하고 있는가?
- instrument_mode: 어떤 종류의 계측기를 사용하고 있는가?
- lto_mode: LTO 모드를 사용하고 있는가?
우리의 경우, compiler_mode는 여기에 표시된 것처럼 항상 LLVM 또는 LTO입니다:
char *callname = argv[0]
...
if (strncmp(callname, "afl-clang-fast", 14) == 0) {
compiler_mode = LLVM;
} else if (strncmp(callname, "afl-clang-lto", 13) == 0 ||
strncmp(callname, "afl-lto", 7) == 0) {
compiler_mode = LTO;
...위의 코드조각은 argv[0]이 afl-clang-fast 또는 afl-clang-lto와 같은지 검사하고 그에 따라 compiler_mode를 설정합니다. LLVM에 초점을 맞추고 있기 때문에 이 두 가지 옵션만 고려할 것입니다. 또한 컴파일러 모드는 환경 변수 AFL_CC_COMPILER에 따라 설정할 수도 있습니다.
instrument_mode는 3곳에서 설정됩니다:
PCGUARD 계측의 경우 여기에 설정됩니다:
if (instrument_mode == 0 && compiler_mode < GCC_PLUGIN) {
...
instrument_mode = INSTRUMENT_PCGUARD;
...
}LTO 계측 기능은 afl-clang-lto 컴파일러를 통해 액세스할 수 있습니다.
if (compiler_mode == LTO) {
if (instrument_mode == 0 || instrument_mode == INSTRUMENT_LTO ||
instrument_mode == INSTRUMENT_CFG ||
instrument_mode == INSTRUMENT_PCGUARD) {
lto_mode = 1;
...
instrument_mode = INSTRUMENT_PCGUARD;
...
}
...
}LTO 모드를 사용하고 있으므로 lto_mode = 1이 표시됩니다.
자, 다시 정리해 보겠습니다. 아래는 결과 변수에 대한 설명입니다:
compiler_mode=LLVM,instrument_mode=INSTRUMENT_PCGUARD,lto_mode=0-afl-clang-fastcompiler_mode=LTO,instrument_mode=INSTRUMENT_PCGUARD,lto_mode=1-afl-clang-lto
이러한 변수를 염두에 두고 이제 컴파일 단계로 넘어갈 수 있습니다. 이를 이해하려면edit_params를 방문해야 합니다.
edit_param에서는 clang에 대한 컴파일러 플래그를 설정합니다.
PCGUARD의 경우 다음 플래그가 설정됩니다:
if (instrument_mode == INSTRUMENT_PCGUARD) {
...
#if LLVM_MAJOR >= 11 /* use new pass manager */
#if LLVM_MAJOR < 16
cc_params[cc_par_cnt++] = "-fexperimental-new-pass-manager";
#endif
cc_params[cc_par_cnt++] = alloc_printf(
"-fpass-plugin=%s/SanitizerCoveragePCGUARD.so", obj_path);
#else
cc_params[cc_par_cnt++] = "-Xclang";
cc_params[cc_par_cnt++] = "-load";
cc_params[cc_par_cnt++] = "-Xclang";
cc_params[cc_par_cnt++] =
alloc_printf("%s/SanitizerCoveragePCGUARD.so", obj_path);
#endif
}LTO의 경우 다음 플래그가 설정됩니다:
if (lto_mode && !have_c) {
...
#if defined(AFL_CLANG_LDPATH) && LLVM_MAJOR >= 15
// The NewPM implementation only works fully since LLVM 15.
cc_params[cc_par_cnt++] = alloc_printf(
"-Wl,--load-pass-plugin=%s/SanitizerCoverageLTO.so", obj_path);
#elif defined(AFL_CLANG_LDPATH) && LLVM_MAJOR >= 13
cc_params[cc_par_cnt++] = "-Wl,--lto-legacy-pass-manager";
cc_params[cc_par_cnt++] =
alloc_printf("-Wl,-mllvm=-load=%s/SanitizerCoverageLTO.so", obj_path);
#else
cc_params[cc_par_cnt++] = "-fno-experimental-new-pass-manager";
cc_params[cc_par_cnt++] =
alloc_printf("-Wl,-mllvm=-load=%s/SanitizerCoverageLTO.so", obj_path);
#endif
...
}PCGUARD와 LTO는 모두 LLVM 패스라는 것을 로드합니다. 제가 알기로는 이 패스는 LLVM(또는 이 경우에는 아웃오브트리 플러그인)이 LLVM 백엔드로 전달되기 전에 LLVM IR을 조작할 수 있는 기회입니다.
LLVM 패스는 여기와 여기에 잘 설명되어 있습니다.
PCGUARD의 경우, 패스 관리자는 SanitizerCoveragePCGUARD.so이고, LTO의 경우, 패스 관리자는 SanitizerCoverageLTO.so입니다.
패스 외에도 오브젝트 파일도 포함되어 있습니다:
if (!shared_linking && !partial_linking)
cc_params[cc_par_cnt++] =
alloc_printf("%s/afl-compiler-rt.o", obj_path);
if (lto_mode)
cc_params[cc_par_cnt++] =
alloc_printf("%s/afl-llvm-rt-lto.o", obj_path);lto_mode를 사용하는 경우 afl-llvm-rt-lto.o도 포함된다는 점에 유의하세요.
LLVM pass plugins
컴파일러 옵션을 염두에 두고 실제 패스 플러그인 자체에 대해 간단히 살펴보겠습니다. 하지만 이 작업을 수행하기 전에 LLVM 아키텍처를 높은 수준에서 이해할 필요가 있습니다.
LLVM의 작동 방식은 아래에 설명되어 있습니다:
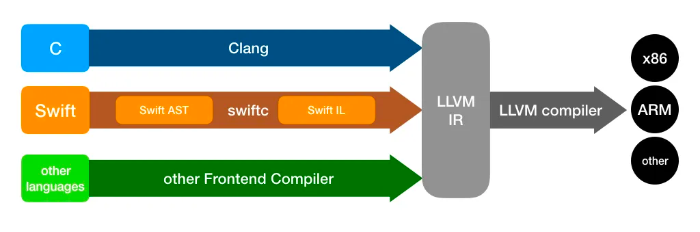
기본적으로 LLVM은 프런트엔드 언어를 가져와서 LLVM IR로 덮어씌웁니다. 이 LLVM IR은 최적화되어 패스를 통해 전송됩니다(당사를 포함한). LLVM 패스가 완료되면 IR은 백엔드 어셈블리 언어로 변환됩니다.
이 때문에 플러그인이 어셈블리 대신 LLVM IR에서 작동하는 것을 볼 수 있습니다.
저는 LLVM에 익숙하지 않으므로 여기서부터 제가 말하는 모든 것을 신중하게 받아들이시기 바랍니다. 수정이나 개선 사항이 있으면 언제든지 이메일을 보내주세요. 기꺼이 듣고 싶습니다.
PCGUARD 플러그인부터 시작하겠습니다: SanitizerCoveragePCGUARD.so. 이 플러그인의 소스는 여기에서 찾을 수 있습니다. 여기에는 많은 내용이 있으므로 중요한 내용에 집중해 보겠습니다.
패스 플러그인은 LLVM 모듈을 가져오는 instrumentModule에서 시작됩니다. 제가 알기로는 LLVM 모듈은 프로그램(또는 객체 파일일 수도 있겠죠?)입니다.
가장 먼저 하는 일 중 하나는 __afl_area_ptr에 대한 전역 변수를 설정하는 것입니다:
AFLMapPtr =
new GlobalVariable(M, PointerType::get(Int8Ty, 0), false,
GlobalValue::ExternalLinkage, 0, "__afl_area_ptr");AFLMapPtr은 GlobalValue::ExternalLinkage(즉, 외부 변수)로 인스턴스화되어 있음을 알 수 있습니다. 이는 실제로 afl-compiler-rt.o.c에 선언되어 있기 때문입니다. 우리는 계측을 위해 이 값에 계속 액세스할 것입니다.
여기에서 필요한 함수를 추가한 다음 모든 함수에 대해 instrumentFunction을 입력합니다:
for (auto &F : M)
instrumentFunction(F, DTCallback, PDTCallback);다음 몇 줄을 이해하려면 LLVM 블록을 이해하는 것이 중요합니다. LLVM에서 각 함수는 "블록"으로 나뉩니다. LLVM 설명서에 따르면 블록(BasicBlock 유형으로 표시)은 "터미네이터 명령어"(즉, 분기)에서 종료되는 연속 IR 명령어 집합입니다. 일단 블록이 입력되면 종료자 명령어(소스) 이외의 다른 포인터에서는 종료되지 않습니다.
이를 염두에 두고, instrumentFunction의 처음 몇 줄을 이해할 수 있습니다.
for (auto &BB : F) {
if (shouldInstrumentBlock(F, &BB, DT, PDT, Options))
BlocksToInstrument.push_back(&BB);위 줄에서는 함수에 있는 각 BasicBlock을 반복하고 shouldInstrumentBlock을 호출합니다. 해당 블록을 계측해야 하는 경우 블록을 BlocksToInstrument라는 벡터에 추가합니다(C++에 익숙하지 않은 경우 벡터는 Java의 ArrayList와 매우 유사합니다).
모든 블록을 BlocksToInstrument에 추가한 다음에는 InjectCoverage를 사용하여 해당 블록에 대한 계측을 수행합니다:
InjectCoverage(F, BlocksToInstrument, IsLeafFunc);InjectCoverage는 마법이 일어나는 곳입니다.
InjectCoverage에서는 호출 인스트럭션과 선택 인스트럭션이라는 두 가지 에지 케이스를 처리합니다. 여기서는 에지 케이스에 대해 설명하지 않겠지만 호출의 경우 호출이 __afl_coverage_interesting이라는 함수에 대한 호출인 경우 특별한 계측을 삽입합니다. 선택은 삼항 연산자와 같은 명령어이며, 몇 가지 특수한 계측을 유도합니다.
이러한 에지 케이스 외에 InjectCoverage도 나쁘지 않습니다. 우리가 하는 한 가지 매우 중요한 일은 "섹션 배열"을 설정하는 것입니다. 이는 다음과 같이 호출되는 CreateFunctionLocalArrays에서 수행됩니다:
CreateFunctionLocalArrays(F, AllBlocks, first + cnt_cov + cnt_sel_inc);그렇다면 섹션 배열이란 무엇일까요? PCGUARD 계측에 대해 설명할 때 커버리지 맵(afl_area_ptr)의 인덱스가 런타임에 어떻게 결정되는지에 대해 이야기했습니다. 좀 더 구체적으로, DAT* 변수에서 인덱스를 가져옵니다. 이러한 DAT* 변수는 실제로 섹션 배열에 있습니다. 따라서 이러한 섹션 배열을 생성하는 것은 실제로 이러한 DAT_* 변수를 위한 공간을 생성하는 것입니다. 이는 함수에서 확인할 수 있습니다:
const char SanCovGuardsSectionName[] = "sancov_guards";
...
void ModuleSanitizerCoverageAFL::CreateFunctionLocalArrays(
Function &F, ArrayRef<BasicBlock *> AllBlocks, uint32_t special) {
if (Options.TracePCGuard)
FunctionGuardArray = CreateFunctionLocalArrayInSection(
AllBlocks.size() + special, F, Int32Ty, SanCovGuardsSectionName);
...
}보시다시피, sancov_guards 섹션에서 AllBlocks.size() 크기의 int 배열을 생성합니다.
이 결과는 실제로 Ghidra에서 sancov_guards라는 섹션이 있는 곳에서 확인할 수 있습니다:

이 배열이 생성되면 실제로 계측을 삽입할 수 있습니다. 이 작업은 InjectCoverageAtBlock에서 수행됩니다. 이 함수는 아래에서 호출됩니다:
if (!AllBlocks.empty())
for (size_t i = 0, N = AllBlocks.size(); i < N; i++)
InjectCoverageAtBlock(F, *AllBlocks[i], i, IsLeafFunc);이 함수는 실제로 마법이 일어나는 곳입니다. 삽입된 계측을 이해하기 위해 코드를 살펴봅시다:
BasicBlock::iterator IP = BB.getFirstInsertionPt();
...
IRBuilder<> IRB(&*IP);
...
Value *GuardPtr = IRB.CreateIntToPtr(
IRB.CreateAdd(IRB.CreatePointerCast(FunctionGuardArray, IntptrTy),
ConstantInt::get(IntptrTy, Idx * 4)),
Int32PtrTy);
LoadInst *CurLoc = IRB.CreateLoad(IRB.getInt32Ty(), GuardPtr);
ModuleSanitizerCoverageAFL::SetNoSanitizeMetadata(CurLoc);
/* Load SHM pointer */
LoadInst *MapPtr = IRB.CreateLoad(PointerType::get(Int8Ty, 0), AFLMapPtr);
ModuleSanitizerCoverageAFL::SetNoSanitizeMetadata(MapPtr);
/* Load counter for CurLoc */
Value *MapPtrIdx = IRB.CreateGEP(Int8Ty, MapPtr, CurLoc);
if (use_threadsafe_counters) {
...//not relevant
} else {
LoadInst *Counter = IRB.CreateLoad(IRB.getInt8Ty(), MapPtrIdx);
ModuleSanitizerCoverageAFL::SetNoSanitizeMetadata(Counter)
/* Update bitmap */
Value *Incr = IRB.CreateAdd(Counter, One);
if (skip_nozero == NULL) {
auto cf = IRB.CreateICmpEQ(Incr, Zero);
auto carry = IRB.CreateZExt(cf, Int8Ty);
Incr = IRB.CreateAdd(Incr, carry);
}
StoreInst *StoreCtx = IRB.CreateStore(Incr, MapPtrIdx);
ModuleSanitizerCoverageAFL::SetNoSanitizeMetadata(StoreCtx);좋아요. 첫 번째는 GuardPtr입니다. GuardPtr은 실제로 DAT_* 변수에 대한 포인터입니다. 이 변수는 (int*)FunctionGuardArray+Idx로 계산되며, 여기서 Idx는 AllBlocks에서 BB의 인덱스입니다.
그런 다음 GuardPtr을 역참조하여 CurLoc을 얻습니다. 이것이 DAT_* 변수의 실제 값입니다. 이것이 __afl_area_ptr에 대한 인덱스가 됩니다.
그런 다음 __afl_area_ptr을 가져와 MapPtr에 저장합니다.
그런 다음 CurLoc과 MapPtr을 합산하여 MapPtrIdx를 얻습니다. C에서는 함수적으로 char* MapPtrIdx = (char*)MapPtr + CurLoc입니다.
여기에서 MapPtrIdx의 값을 로드하고 1을 더합니다. 0을 원하지 않으면 *MapPtrIdx+1 == 0이면 1을 더합니다. 이는 커버리지 계측 섹션의 어셈블리 덤프에서 본 adc dl, 0x1과 동일합니다.
그런 다음 새 커버리지 값을 MapPtrIdx에 저장합니다.
C에서는 대략 다음과 같이 나옵니다:
int* FunctionGuardArray = [some offset into sancov_guards];
char* MapPtr = __afl_area_ptr;
int* GuardPtr = FunctionGuardArray+Idx;
int CurLoc = *GuardPtr;
char* MapPtrIdx = MapPtr[CurLoc];
char Counter = *MapPtrIdx;
if(!++Counter){
Counter = 1;
}
*MapPtrIdx = Counter;모든 계측을 삽입한 후 다시 instrumentModule로 돌아가서 한 가지 더 해야 할 일이 있는데, 바로 init 함수를 삽입하는 것입니다. 이러한 초기화 함수는 .init_array에 있는 함수 중 일부입니다. 아래에서 확인할 수 있습니다:
const char SanCovModuleCtorTracePcGuardName[] =
"sancov.module_ctor_trace_pc_guard";
...
const char SanCovTracePCGuardInitName[] = "__sanitizer_cov_trace_pc_guard_init";
...
const char SanCovGuardsSectionName[] = "sancov_guards";
...
if (FunctionGuardArray)
Ctor = CreateInitCallsForSections(M, SanCovModuleCtorTracePcGuardName,
SanCovTracePCGuardInitName, Int32PtrTy,
SanCovGuardsSectionName);위의 함수는 .init_array에 sancov.module_ctor_trace_pc_guard를 가리키는 항목을 생성합니다. 이 생성자는 실제로는 sancov_guards를 초기화하는 __sanitizer_cov_trace_pc_guard_init에 대한 트램펄린일 뿐입니다. 아래에서 볼 수 있듯이 __sanitizer_cov_trace_pc_guard_init의 매개변수는 sancov_guards의 시작과 끝입니다:
std::tie(CtorFunc, std::ignore) = createSanitizerCtorAndInitFunctions(
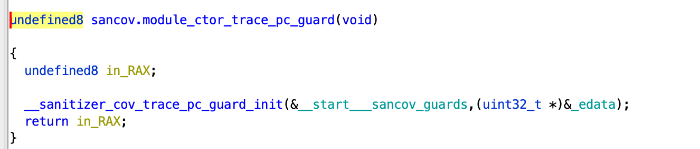
M, CtorName, InitFunctionName, {Ty, Ty}, {SecStart, SecEnd});이는 Ghidra에서도 볼 수 있습니다:
init_array entry:

__sanitizer_cov_trace_pc_guard_init call:
이것으로 PCGUARD 계측기 소개를 마칩니다!
LTO 플러그인의 핵심은 놀라울 정도로 유사합니다. 유일한 두 가지 차이점은 GuardPtr에서 로드하는 대신 전역 변수를 CurLoc으로 사용하고 다른 초기화 함수를 사용한다는 점입니다.
이는 InjectCoverageAtBlock의 소스에서 확인할 수 있습니다.
++afl_global_id;
...
ConstantInt *CurLoc = ConstantInt::get(Int32Tyi, afl_global_id);이 경우 afl_global_id는 인덱스이며 계측을 삽입할 때마다 증가합니다.
또한 초기화 함수도 다릅니다. 구체적으로, sancov.module_ctor_trace_pc_guard를 사용하는 대신 __afl_auto_init_global을 사용합니다. 실제로 아래에서 볼 수 있듯이 IR에서 해당 함수를 실제로 구성합니다:
Function *f = M.getFunction("__afl_auto_init_globals");
...
BasicBlock *bb = &f->getEntryBlock();
...
BasicBlock::iterator IP = bb->getFirstInsertionPt();
IRBuilder<> IRB(&(*IP));
...
if (getenv("AFL_LLVM_LTO_DONTWRITEID") == NULL) {
uint32_t write_loc = afl_global_id;
write_loc = (((afl_global_id + 8) >> 3) << 3);
GlobalVariable *AFLFinalLoc =
new GlobalVariable(M, Int32Tyi, true, GlobalValue::ExternalLinkage, 0,
"__afl_final_loc");
ConstantInt *const_loc = ConstantInt::get(Int32Tyi, write_loc);
StoreInst *StoreFinalLoc = IRB.CreateStore(const_loc, AFLFinalLoc);
ModuleSanitizerCoverageLTO::SetNoSanitizeMetadata(StoreFinalLoc);
}위 코드에서는 기본적으로 IR 코드를 삽입하여 __afl_final_loc = afl_global_id를 설정합니다.
이는 Ghidra의 LTO 바이너리에서도 볼 수 있습니다:

이것으로 계측이 끝났습니다! 이 모든 IR이 삽입되면 IR 코드가 백엔드로 전송되어 원시 어셈블리로 전환됩니다.